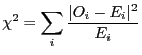Next: B. Formulas and Derivations Up: Where to Stop Reading a Ranked List? Previous: Bibliography
To determine the quality of the fits, we bin the scores and calculate the
![]() statistic
statistic
where
The statistic follows, approximately, a ![]() distribution with
distribution with ![]() degrees of freedom,
where
degrees of freedom,
where ![]() is the number of bins and
is the number of bins and ![]() is the number of parameters we estimate.
The null hypothesis
is the number of parameters we estimate.
The null hypothesis
![]() is that the observed data
follow the estimated mixture.
is that the observed data
follow the estimated mixture.
![]() is rejected
if the
is rejected
if the ![]() of the fit is above the critical value of the corresponding
of the fit is above the critical value of the corresponding
![]() distribution at a significance level of 0.05 [15].
distribution at a significance level of 0.05 [15].
For the ![]() approximation to be valid,
approximation to be valid, ![]() should be at least 5,
thus we may combine bins in the right tail when
should be at least 5,
thus we may combine bins in the right tail when ![]() . When the
last
. When the
last ![]() does not reach 5 even for
does not reach 5 even for ![]() , we only then apply
the Yates' correction, i.e. subtract 0.5 from the absolute difference
of the frequencies in Equation 17 before squaring.
, we only then apply
the Yates' correction, i.e. subtract 0.5 from the absolute difference
of the frequencies in Equation 17 before squaring.
Different fits on the same data can result
to slightly different degrees of freedom due to combining bins.
To compare the quality of different fits,
so we can keep track of the best one irrespective
its
![]() status,
we use the
status,
we use the ![]() upper-probability;
the higher the probability, the better the fit.
As an initial upper-probability reference,
we use the one of an exponential-only fit,
produced by setting
upper-probability;
the higher the probability, the better the fit.
As an initial upper-probability reference,
we use the one of an exponential-only fit,
produced by setting
![]() .
.
The ![]() statistic is sensitive to the choice of bins.
statistic is sensitive to the choice of bins.
For binning, we use the optimal number of bins as this is given by the method described in [12]. The method considers the histogram to be a piecewise-constant model of the underlying probability density. Then, it computes the posterior probability of the number of bins for a given data set. This enables one to objectively select an optimal piecewise-constant model describing the density function from which the data were sampled. For practical reasons, we cap the number of bins to a maximum of 200.
avi (dot) arampatzis (at) gmail