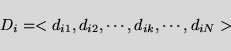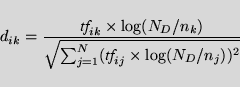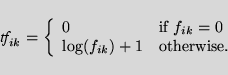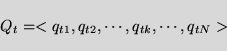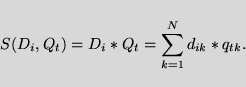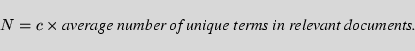Our main concern is to evaluate different indexing schemes.
Document classification, categorization, or routing environments provide
a good test-bed for such evaluations.
In such environments, given a pre-classified corpus,
the measurement of recall is straightforward,
while for classical retrieval systems it involves expensive human judgments.
The experimental system is based on the vector space model,
terms are weighted in a
![]() fashion,
and classifiers are constructed
automatically using Rocchio's (original) relevance feedback method.
We are aware that the choices of retrieval model,
weighting scheme, and classifier construction method
may have a fairly significant impact on performance,
but since we are more interested in the comparative performance of
the different indexing schemes we settle for widely accepted and proven
methods.
fashion,
and classifiers are constructed
automatically using Rocchio's (original) relevance feedback method.
We are aware that the choices of retrieval model,
weighting scheme, and classifier construction method
may have a fairly significant impact on performance,
but since we are more interested in the comparative performance of
the different indexing schemes we settle for widely accepted and proven
methods.
The same goes for the evaluation measures. Instead of making a binary decision to either assign or not a document to a class, we allow the system to return a traditional ranked list of documents for every class: most relevant first, least relevant last. Thus, evaluation is done with 11-point interpolated recall-precision and average precision on a dataset from the Reuters-21578 text categorization test collection. Next we discuss in more detail the methods used, the dataset and pre-processing applied to it.
In the Vector Space Model [15]
documents are represented as vectors of weights:
Classification queries (or classifiers) are represented in the same manner,
e.g. for a topic t
To compute the similarity
between a query Qt and a document Di
we used the dot product formula
Classifiers were constructed automatically by applying Rocchio's relevance feedback method [13] on a pre-classified set of documents (training set). Rocchio's algorithm is a well-known algorithm in the IR community, traditionally used for relevance feedback. Classifiers based on Rocchio have proven to be quite effective in filtering [16] and classification [12,8] tasks.
When training documents are to be ranked for a topic, an ideal classifier should rank all relevant documents above the non-relevant ones. However, such an ideal classifier might just not exist, therefore, we settle for a classifier that maximizes the difference between the average score of relevant and the average score of non-relevant documents.
If the similarity between topics and documents is calculated
by the cosine measure (equation 5),
and document vectors are weighted
and length normalized such as
![]() ,
then Rocchio specifies that the optimal classification query Qt
for topic t
should have term k weighted as
,
then Rocchio specifies that the optimal classification query Qt
for topic t
should have term k weighted as
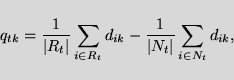 |
(6) |
Term selection (also called feature selection or feature reduction in classification) is an important task. Training data usually contain too many terms, thus it is not uncommon to end up with thousands of terms in the indexing vocabulary. Applying feature reduction techniques to text classification tasks was found not to impair classification accuracy, even for reductions up to a factor of ten [20,12]. This is also economical in time and space.
The answer to the question of how many terms are sufficient
for a topic representation is rather topic dependent and should
be determined experimentally.
However, assuming that relevant documents are likely to look
more like each other (even in their lengths)
than non-relevant documents do,
a sensible number of terms would be a number
proportional to the expected
average number or unique terms in relevant documents:
The average number of unique terms in relevant documents was calculated on the training data. The value of the constant c was estimated experimentally for our dataset. After a few tuning experiments, we set c=0.4. Only the terms with the top N (equation 7) Rocchio weights were selected for every classifier and the rest were removed. This resulted in a great reduction in the number of terms without significant drop in performance. It should be noted that c was tuned for Sw, and assumed to hold for all other experiments as well, suggesting that the Sw experiment may be favored over the rest.
We evaluated on a dataset from the Reuters-21578 (distribution 1.0) text categorization test collection, a resource freely available for research in Information Retrieval, Machine Learning, and other corpus-based research1.
We produced the Modified Apte (ModApte) split (training set: 9,603 documents, test set: 3,299 documents, unused: 8,676 documents). The ModApte split is a subset of the Reuters documents which are about economic topics, such as income, gold and money-supply. [7] discuss some examples of the policies (not always obvious) used by the human indexers in deciding whether a document belongs to a particular topic category.
Because Rocchio's algorithm requires each training document to have at least one topic, we further screened out the training documents with no topics category. Of course, we did not remove any of the 3,299 test documents, since that would have made our results incomparable with other studies. Documents can have assigned more than one topic, i.e. multi-classification. We used only the topics which have at least one relevant training document and at least one relevant test document (90 topics in total).
Since there is a large variation in the numbers of relevant training documents for topics, we evaluate separately on small and large topics. As small topics are considered the ones which have ten or less training documents (32 in total), and the rest (58 in total) are considered as large.
In order to obtain for every experiment the appropriate indexing terms from the dataset, we applied some pre-processing. The pre-processing was performed in six steps:
For Sw, words were stemmed using the Porter stemmer of the Lingua::Stem (version 0.30) extension to PERL.