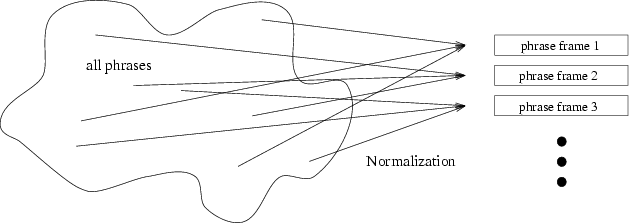
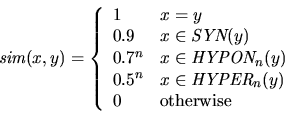The goal of normalization is to map different but semantically equivalent
phrases onto one canonical representative phrase,
the phrase frame (figure 2).
Morphological normalization has traditionally been performed by means of stemming. Non-linguistic stemming, especially when it operates in the absence of any lexicon at all, is rather aggressive and may result in improper conflations. For instance, a Porter-like stemmer without a lexicon will reduce university to universe and organization to organ. Errors like these are translated into a loss in retrieval precision. This impact is greater for more inflected languages than English, because of the increased number of introduced ambiguities. Such improper conflations can be avoided by simply checking for existence of the word-form in a lexicon after each reduction step. Nevertheless, the verb forms attached and suited will still be reduced wrongly to the nouns attache and suite respectively.
Taking into account the linguistic context, a more conservative approach will prevent many of these errors. Conflations can be restricted to retain the part-of-speech of a word. In this respect, morphological normalization may be performed by means of lemmatization:
Lemmatization is relatively simple and handles mostly inflectional morphology. It is similar to the lexicon-based word normalization, as referred to in [27]. It must be noted that there are cases where lemmatization reduces noun and verb forms to the same lemma. Consider for instance the verb form attacked and the plural noun attacks; both will be lemmatized as attack. Although such conflations seem beneficial, there are indications from a text filtering experiment that the confusion between nouns and verbs when these are lemmatized, decreases effectiveness [28].
Derivational morphology involves semantics and cross part-of-speech word relations, hence should be approached carefully. Certain derivational transformations may be suggested by syntax. For instance, verbs may be turned into nouns (nominalization) or the other way around as it will be shown in the next section. The remaining derivational morphology should be treated, where possible, by lexico-semantical normalization.
According to the linguistic principle of headedness,
any phrase has a single head. This head is usually a noun
(the last noun before the post-modifiers) in NPs,
the main verb in the case of VPs.
The rest of the phrase consists of modifiers.
Consequently, every phrase can be mapped onto a phrase frame:
Heads and modifiers in the form of phrases are recursively defined as phrase frames: [[h1,m1],[h2,m2]]. The modifier part may be empty in case of a bare head. This case is denoted equivalently by [h,] or [h]. The head may serve as an index for a list of phrases with occurrence frequencies:
[ engineering 1026 ,
of software 7 ;
reverse 102 ;
software 842 ;
... ]
where the frequency of a bare head includes that of its modified occurrences.
Alternative modifications of the head are separated by semicolons.
Phrases frames are produced by normalizing the phrase representations of definitions 3 and 4. In noun phrases, determiners are of little interest for IR, thus they may be eliminated. The normalization of noun phrase is defined as:
The elements of the list
a special lecture on software engineeringPrepositions (e.g. on in the last example) may optionally be kept for further semantic analysis, although their use is usually dropped for simplicity. However, it must be noted that the space-man on the ship enjoys a different view than the space-man outside the ship and the space-man without ship is probably not even in space. The impact of prepositions on retrieval performance is not well-established, but their careful treatment may be beneficial. Their use and meaning can always be postponed until the matching of PFs. Prepositions, conjuctions and such other lexical items were considered as connectors in the characterization language of index expressions [29].
The noun phrase presents only a few opportunities for
syntactical normalization.
For the verb phrase, more normalizations can be found
which preserve its meaning, or rather do not loose information
obviously relevant for retrieval purposes.
To begin with the kernel,
elimination of time, modality and voice seems resonable.
The obviously meaningful head-modifier combinations are
![]() and
and
![]() :
:
For example,
the students will probably attend a special lecture on MondayIn the definition 6 the adverbs of the kernel are eliminated. Small experiments have suggested that adverbs have a little indexing value [28]. However, they might be more useful if they combine with the verbs (or adjectives in the case of noun phrase) they modify, e.g. [attend, probably]. The indexing value of such verb-adverb and adjective-adverb pairs has to be evaluated empirically.
The possibility exists to map verbs to nouns (nominalization) or vice versa (verbalization). Such a normalization allows the matching of PFs derived from different sources (verb phrases or noun phrases). For example, (to) implement can be nominalized to implementation. Since the opposite transformation is also possible for nominalized verb forms, the choice has to be made on the basis of experimentation. We will presently choose to turn everything into ``pictures'' (noun phrases) by applying the former alternative. This results in a more drastic (and compact) normalization:
the students will probably attend a special lecture on MondaySimilarily, adverbs may be mapped onto adjectives to modify the nominalized verbs, e.g. [attendance, probable]. Cross part-of-speech transformations like these controlled by syntax can deal to some extent with derivational morphology, compensating for the conservative nature of lemmatization described in the previous section. The further application of the noun phrase normalization to the last phrase frame, results eventually in:
[attendance, students; [lecture, special]; on [Monday]]
All these normalizations are rather language dependent and the final decision of what has to be included in the phrase frames should be left to the linguists and system designers; we have merely suggested some obvious ones.
This kind of normalization depends on the observation that certain relations can be found between the meaning of individual words. The most well-known of those lexico-semantical relations are:
A word is polysemous if its meaning depends on the context. For example, by itself the noun note can be meant as a being a short letter, or as a musical note, consequently its context has to clarify its meaning. The intended meaning determines the words which are lexico-semantically related to the initial word. Using the synonymy relation for the first meaning we can obtain brief, while tune is obtained in the second case. This suggests that the conceptual context of a word should be taken into account.
Collocations are two or more words which often co-occur adjacent, e.g. health care, having a certain meaning. When using WORDNET in expanding a query with hypernyms, the notion health care obtains social insurance which cannot be obtained in any case by expanding the two separate words. This observation suggests that collocations should be considered as single units.
Assuming that the word sense ambiguity originating from polysemy is resolved, three possibilities can been seen for lexico-semantical normalization:
Working out fuzzy matching a bit more,
using only the relations
![]() onymy,
onymy,
![]() nymy, and
nymy, and
![]() nymy
between two words x and y,
one could define:
nymy
between two words x and y,
one could define:
As an example of fuzzy matching, consider the sentence
The students will probably attend a conference on software engineering.from which, after syntactical and morphological normalization and elimination of some (assumed) redundant elements, the following phrase frame may be constructed:
[attendance, student; conference; [engineering, software]]Now let us consider another sentence
The pupils are listening carefully to the tutorial about software engineering.which in a phrase frame representation becomes:
[listening, pupil; tutorial; [engineering, software]]Note that listening here represents the nominalized form (the listening) of the verb to listen rather than its progressive form. Using WORDNET's lexical graph, and assuming that the latter sentence is a part of a natural language description of a user's information need (query), the following relations hold: