Term weighting
is a crucial part of any information retrieval system.
Statistical weighting schemes like tf.idf,
which perform well for single terms,
do not seem to extent on multi-word terms.
Most work on the use of multi-word indexing terms
in IR concentrated on representation and matching strategies.
Little consideration was given to weighting and to scoring of
documents matched.
An obvious weighting strategy for phrasal terms is to
weight a term as a function of the weights of its components.
However, such strategies did not produce uniform results
[18,30].
We suggest a simple weighting scheme suitable for phrase frames
which takes into account the modification structure and its depth.
Phrase frames may contain nested phrase frames (sub-frames) at different depths.
To simplify the structural matching of complicated phrase frames,
the strategy of unnesting can be followed.
The unnesting of a phrase frame produces all possible sub-frames
down to single-term frames.
This can be understood easier,
by visualizing a phrase frame as a tree;
the root-node is the main head, and every node is modified by its child-nodes.
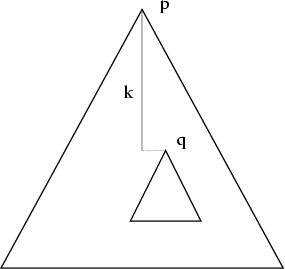
Such an abstract tree is depicted in figure 3.
First we introduce the predicate
![]() as a shorthand for the expression:
phrase frame p has phrase frame q as a sub-frame at depth k.
The depth weight of sub-frame q obtained from frame pcan be expressed as:
as a shorthand for the expression:
phrase frame p has phrase frame q as a sub-frame at depth k.
The depth weight of sub-frame q obtained from frame pcan be expressed as:
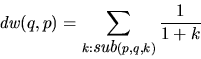

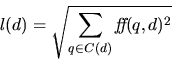
The similarity between a document d and a query q then
is estimated by the dot product formula: