Next: 3 Score Distributions Up: Where to Stop Reading a Ranked List? Previous: 1 Introduction
Essentially, the task of selecting ![]() is equivalent to thresholding
in binary classification or filtering. Thus, we recruited and adapted a method
first appeared in the TREC 2000 Filtering Track, namely, the
score-distributional threshold optimization (s-d)
[2,3].
is equivalent to thresholding
in binary classification or filtering. Thus, we recruited and adapted a method
first appeared in the TREC 2000 Filtering Track, namely, the
score-distributional threshold optimization (s-d)
[2,3].
Let us assume an item collection of size ![]() , and a query for which
all items are scored and ranked. Let
, and a query for which
all items are scored and ranked. Let ![]() and
and ![]() be the
probability densities of relevant and non-relevant documents as a
function of the score
be the
probability densities of relevant and non-relevant documents as a
function of the score ![]() , and
, and ![]() and
and ![]() their
corresponding cumulative distribution functions (cdfs). Let
their
corresponding cumulative distribution functions (cdfs). Let
![]() be the fraction of relevant documents in the
collection of all
be the fraction of relevant documents in the
collection of all ![]() documents, also known as generality.
The total number of relevant documents in the collection is given by
documents, also known as generality.
The total number of relevant documents in the collection is given by
Let us now assume an effectiveness measure ![]() of the form
of a linear combination the document counts of the categories
defined by the four combinations of relevance and retrieval status,
for example a linear utility [18].
From the property of expectation linearity,
the expected value of such a measure would be the same linear
combination of the above four expected document numbers.
Assuming that the larger the
of the form
of a linear combination the document counts of the categories
defined by the four combinations of relevance and retrieval status,
for example a linear utility [18].
From the property of expectation linearity,
the expected value of such a measure would be the same linear
combination of the above four expected document numbers.
Assuming that the larger the ![]() the better the effectiveness,
the optimal score threshold
the better the effectiveness,
the optimal score threshold ![]() which maximizes the expected
which maximizes the expected
![]() is
is
So far, this is a clear theoretical answer to predicting ![]() for linear effectiveness measures.
In Section 2.3 we will see how to deal with non-linear measures,
as well as, how to predict rank (rather than score) cut-offs.
for linear effectiveness measures.
In Section 2.3 we will see how to deal with non-linear measures,
as well as, how to predict rank (rather than score) cut-offs.
Given the two densities and the generality defined earlier, scores can be normalized to probabilities of relevance straightforwardly [2,14] by using the Bayes' rule.
Normalizing to probabilities
is very important in tasks where several rankings need to be fused or merged
such as in meta-search/fusion or distributed retrieval.
This may also be important
for thresholding when documents arrive one by one and decisions have to
be made on the spot, depending on the measure under optimization.
Nevertheless, it is unnecessary for thresholding rankings
since optimal thresholds can be found on their scores directly,
and it is furthermore unsuitable given ![]() as the evaluation measure.
as the evaluation measure.
While for some measures there exists an optimal fixed
probability threshold, for others it does not. Lewis [13]
formulates this in terms of whether or not a measure satisfies the
probability thresholding principle, and proves that the ![]() measure does not satisfy it. In other words, how a system should
treat documents with, e.g., 50% chance of being relevant depends on
how many documents with higher probabilities are available.
measure does not satisfy it. In other words, how a system should
treat documents with, e.g., 50% chance of being relevant depends on
how many documents with higher probabilities are available.
The last-cited study also questions whether, for a given measure, an
optimal threshold (not necessarily a probability one) exists, and goes
on to re-formulate the probability ranking principle for
binary classification. A theoretical proof is provided about the
![]() measure satisfying the principle, so such an optimal threshold
does exist. It is just a different rank or score
threshold for each ranking.
measure satisfying the principle, so such an optimal threshold
does exist. It is just a different rank or score
threshold for each ranking.
Non-linearity complicates the matters in the sense that the expected
value of ![]() cannot be easily calculated. Given a ranked list, some
approximations can be made simplifying the issue. If
cannot be easily calculated. Given a ranked list, some
approximations can be made simplifying the issue. If ![]() ,
, ![]() ,
and
,
and ![]() are estimated on a given ranking, then
Equations 2-5 are good approximations of
the actual document counts. Plugging those counts into
are estimated on a given ranking, then
Equations 2-5 are good approximations of
the actual document counts. Plugging those counts into ![]() ,
we can now talk of actual
,
we can now talk of actual ![]() values rather than expected.
The score threshold which maximizes
values rather than expected.
The score threshold which maximizes ![]() is given
by Equation 6.
is given
by Equation 6.
While ![]() can be optimal anywhere in the score range, with respect to
optimizing rank cutoffs we only have to check its value at the scores
corresponding to the ranked documents, plus one extra point to allow
for the possibility of an empty optimal retrieved set. Let
can be optimal anywhere in the score range, with respect to
optimizing rank cutoffs we only have to check its value at the scores
corresponding to the ranked documents, plus one extra point to allow
for the possibility of an empty optimal retrieved set. Let ![]() be
the score of the
be
the score of the ![]() th ranked document, and define
th ranked document, and define ![]() as follows:
as follows:
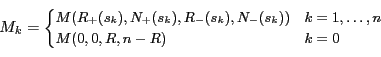
The optimal rank
avi (dot) arampatzis (at) gmail